- What storing blobs in databases means
- Storage of blobs outside the database
- Risk and cost analysis
- Conclusion
In many web applications, files have to be processed and then persisted over the long term. A recurring decision when defining system architectures is where these binary large objects - or blobs for short - should be kept. In the following we will look at the disadvantages of storing blobs within the database management system and what alternatives there are.
Simple user stories such as
As a user, I would like to be able to upload a profile photo.
or
As a user, I would like to be able to attach an Excel/PDF file to my domain object.
tempt you to choose a supposedly simple technical solution: namely saving the profile photo or the Excel or PDF file within the database. The following extract from database modeling can therefore often be found in many applications:
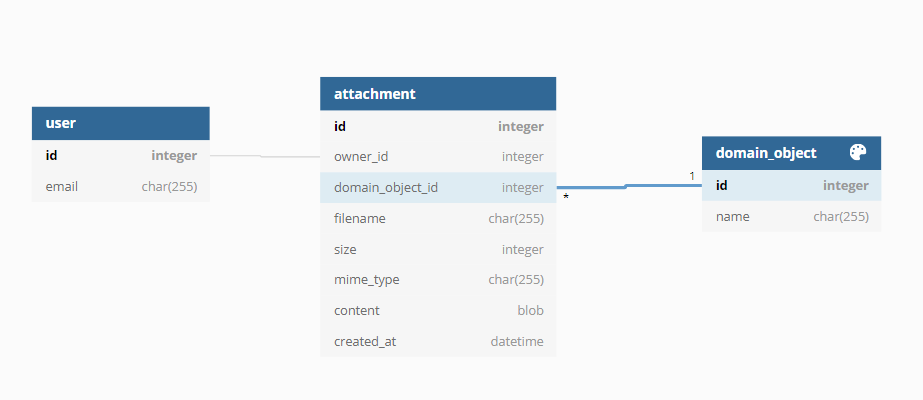
Depending on the framework used, the byte stream can be saved quickly in the attachment table. Any authorizations to be implemented subsequently for the file download can easily be implemented. The user story is thus implemented. During the test phase or go-live with a few users and a correspondingly low load, the web application can be accessed as desired. The client is satisfied for the time being.
What storing blobs in databases means
Direct consequences of storing the blobs in the database
Saving the file attachments in the attachment table increases the total size of the database. In relation to the pure (text) data, blobs contribute most to the increase in volume. This in turn means:
- The hard disk or the file system on which the database data is located, for example
/var/lib/postgres, fills up over time. - Exports from the underlying database take longer.
- The load during replication of databases increases.
The database size can grow much faster than originally planned: With SaaS applications, this can often happen in the start-up phase due to rapid growth in the user base. Otherwise, bugs may have arisen during implementation or boundary conditions may not have been considered:
- Existing files are not replaced when they are uploaded again, but appended.
- There is no limit to the size of attached files.
Overflowing filesystem through blobs
Depending on the partitioning of the operating system environment, a full file system can ensure that a login via SSH is no longer possible without further ado. In the simplest case, no more write changes can be made within the database. This means that changes to other tables also fail and the web application can no longer be used without restrictions.
Since the blobs cannot be easily deleted from the database, the file system must either be enlarged or the database must be moved to a file system with free space.
Database exports take longer
The more data that is kept in the database, the longer it takes to export the data. This can be neglected in the short term, but can be problematic for productive operation in the long term.
On the other hand, it is more problematic if data from the productive database for the QA environment is regularly anonymized and exported. Within a continuous integration / deployment process, this can happen more often every day and creates additional load on the productive database. Here you have to weigh up whether you really need hourly or even up-to-the-minute data. Otherwise, the exports can be cached and reused later.
In the event that the latest version of the productive database has to be imported, the file attachments should be excluded from the export. Depending on the environment, this can be more difficult to implement and increases the complexity of the export process.
Increased load while replicating data
This only applies to applications for which horizontal scaling for the databases has already been planned in advance. More replication load is created between the primary and secondary nodes. In unfavorable cases, this can ensure that the replication falls into the out-of-sync status.
Recovery of individual blobs
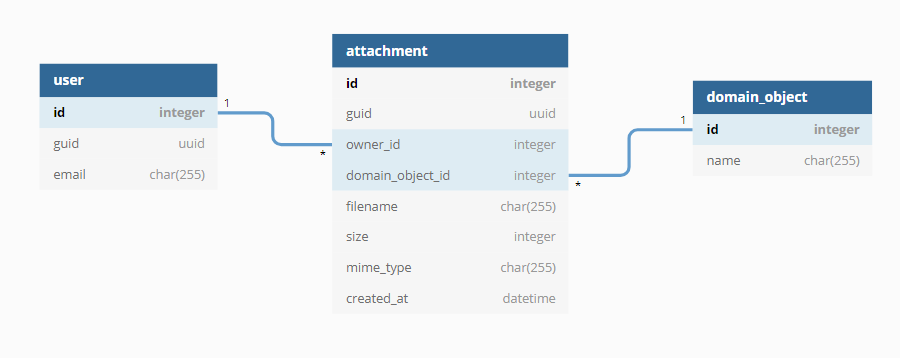
Due to compliance requirements, it may be necessary for data records to be historized and/or recoverable. The historization of the files can be implemented by persisting a new tuple in the database for each new blob. However, this means that every new version of a blob has to be saved in full in the database.
Oracle’s Advanced LOB Deduplication allows deduplication. MySQL and PostgreSQL, however, do not have such a feature.
Follow-up problems during the software implementation phase
The problems described above are more of a theoretical nature during software development. Either the database administrators or the DevOps team are responsible for solving operational problems.
However, as soon as parts of the application show performance problems, the software development team is consulted first. The following sequence diagram illustrates the process as soon as blobs are to be loaded from the database. Blob service is interchangeable with application server, microservice, web server or a PHP script.
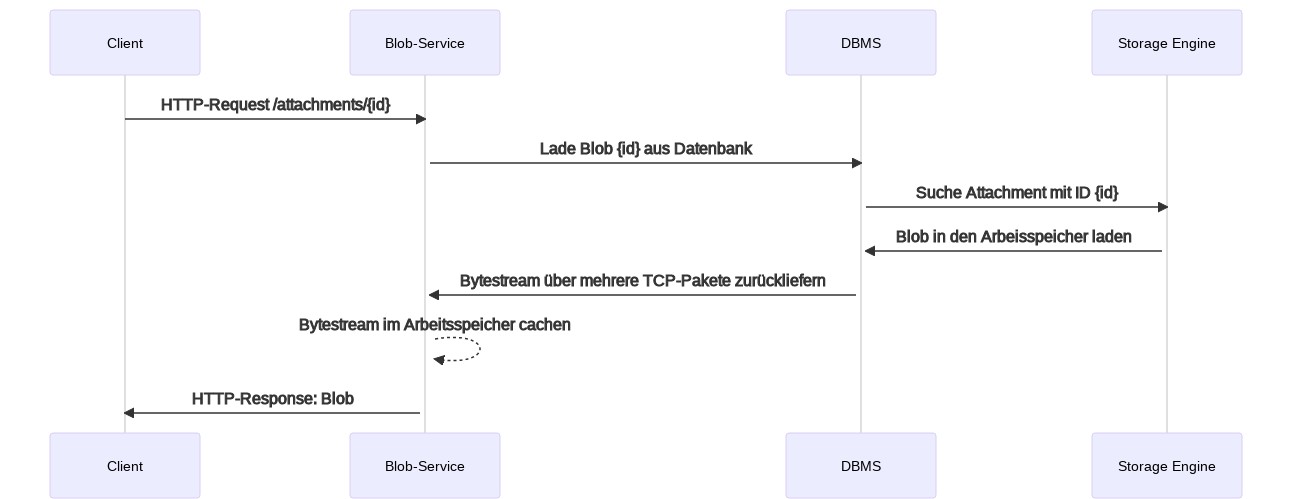
For every request for a blob by the client, both the blob service and the DBMS are involved. The response times thus increase.
Memory usage
For each requested blob, the service must first search for the assigned tuple in the database. The DBMS returns the data record via the TCP protocol. The service extracts the blob from the tuple and then returns it to either the web or application server.
Normal applications generate a high level of memory consumption: the entire byte stream of the blob must be kept in memory during the request. In the case of a 20 MByte file, an additional 20 MBytes would be kept in the main memory both on the DBMS side and on the part of the blob service. Even with a few simultaneous requests, this can lead to full utilization of the main memory.
Reactive applications, like using Spring WebFlux in combination with R2DBC, can return individual chunks of the blob to the client. This minimizes the memory consumption. However, the complexity of the application or the microservice increases.
Upload of blobs
In addition to the download of files, the upload must also be considered. Depending on the technology used, the appropriate configuration parameters must be set so that larger files can be uploaded at all:
| Platform | Configuration parameter |
|---|---|
| PHP | upload_max_filesize and post_max_size |
| MySQL | max_allowed_packet |
| Spring (Boot) | spring.servlet.multipart.max-file-size and spring.servlet.multipart.max-request-size |
Here, too, it is important that the underlying operating system has sufficient RAM, otherwise Java-based applications can crash with java.lang.OutOfMemoryError: Java heap space. In the case of PHP-based applications, it may also be necessary to adjust the memory_limit parameter if the uploaded file is processed in the main memory. This can be the case, for example, when compressing or scaling images.
Caching
The blob service can implement caching to reduce response times. Caching the pure blobs within the main memory is impractical due to the byte size. Instead, the blob service can use the HTTP header Cache-Control to influence when the client can request new versions of a blob.
Storage of blobs outside the database
In order to avoid the problems discussed so far, one of the following alternatives can be considered:
- The blob service delivers the blobs directly from the local hard drive or a distributed file system (e.g. NFS, EFS). The delivery can either take place from the web server or application server or the application. The metadata of the blob is still stored in the database.
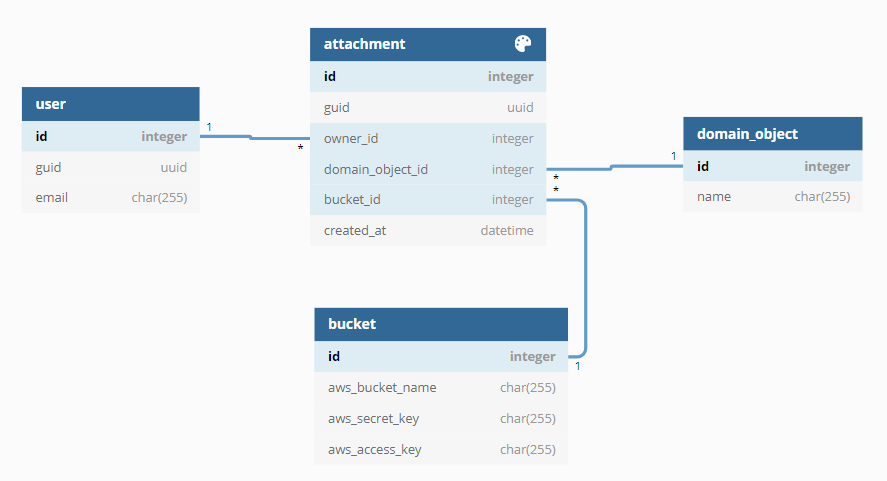
- A dedicated object storage, e.g. AWS S3, Azure Blob Storage, Minio or NetApp StorageGRID is used. The metadata is stored in the database management system and/or in the object storage.
Direct delivery of the blobs by the service
Web servers are designed to provide static content - i.e. uploaded blobs - with high performance. If the blob service takes care of the delivery of the files, this can be done either with or without the involvement of the web or application server. The metadata is stored within the database so that the web application can display information about the blob directly to the user.
Both procedures have in common that the blobs are saved in the connected file system. The defined backup strategy can integrate these files so that old versions of the blobs can be restored.
Redirect via a URL
With this method, the application generates a URL to a directory that is processed directly by the web or application server. The files are saved in a directory structure in which the context - e.g. B. the GUID of the current tenant - is stored. The file name itself is replaced with a random ID or GUID.
Advantages:
- Implementation is comparatively easy.
- Very high-performance, as the web server alone provides the files.
- Compression of the blobs during the transfer can be done directly by the web server.
Disdvantages:
- Authorization for the files to be downloaded is not possible or only with additional effort on the part of the web server.
- Obfuscation of the file name is not a security measure.
- Obfuscation of the file name is also often not desired by the customer.
Push through the blob service
When requested by the client, the blob service generates the appropriate HTTP headers based on the metadata. The original file name can also be sent to the client. The blob service then loads the file into the main memory and then sends its byte stream to the client.
Advantages:
- Authorization for blobs can be done within the application. Trying out URLs does not give any result.
- The original file name, MIME type and other metadata are retained during the download.
Disdvantages:
- Additional RAM is required during the download.
- Logic to provide the download must be implemented in the application.
Delivery of blobs by an object storage
Object storages specialize in providing individual blobs via a unique URL. With the help of AWS S3 or Azure Blob, for example, URLs that are valid for a limited time can be generated in which a file can be downloaded or uploaded. Depending on the object storage, there are solutions for versioning and also the possibility of moving the blobs to slower, and thus cheaper, storages.
Although AWS S3 can store metadata, this is often also stored in the database. This reduces the number of requests to S3's API.
Advantages:
- Upload and download are completely relocated outside of the application. A CDN such as CloudFront, for example, can be used, especially if scaling becomes necessary later.
- Data backup by the object storage provider.
Disadvantages:
- Possibly compliance problems if the files are stored with a cloud provider.
- If necessary, depending on the product used, additional costs for traffic and API requests.
Risk and cost analysis
| Persisting blobs in ... | Risk | Expected cost factors |
|---|---|---|
| Database | High |
|
| local or distributed filesystem | Average |
|
| Object Storage | Low |
|
Conclusion
Even if storing blobs within a database looks attractive at first glance, we advise against such an architecture decision. Depending on the risk assessment and the available budget, we recommend either the use of a local or distributed file system and provision of the blobs by the application or the use of a suitable object storage.
