
-
Was das Speichern von Blobs in Datenbanken bedeutet
- Direkte Konsequenzen durch die Speicherung der BLOBs innerhalb der Datenbank
- Volllaufendes Dateisystem durch Blobs
- Exporte der Datenbank dauern länger
- Höhere Last während der Replizierung von Daten
- Wiederherstellung von einzelnen Blobs
- Folgeprobleme während der Software-Implementierungsphase
- Speicherverbrauch
- Upload von Blobs
- Caching
- Speicherung von Blobs außerhalb der Datenbank
- Risiko- und Kostenbetrachtung
- Fazit
In vielen Web-Applikationen müssen Dateien verarbeitet und dann langfristig persistiert werden. Eine immer wiederkehrende Entscheidung während der Definition von Systemarchitekturen ist, wo diese Binary Large Object – oder kurz Blobs – vorgehalten werden sollen. Im Folgenden werden wir auf die Nachteile bei der Speicherung von Blobs innerhalb des Datenbankmanagementsystems eingehen und welche Alternativen es dazu gibt.
Einfache User Stories wie z. B.
Als Benutzer möchte ich ein Profilfoto hochladen können.
oder
Als Benutzer möchte ich meinem Domänenobjekt eine Excel-/PDF-Datei anhängen können.
verleiten dazu, eine vermeintlich einfache technische Lösung zu wählen: Nämlich das Speichern des Profilfotos oder der Excel- bzw. PDF-Datei innerhalb der Datenbank. Der folgende Auszug einer Datenbankmodellierung lässt sich dementsprechend oft in vielen Applikationen finden:
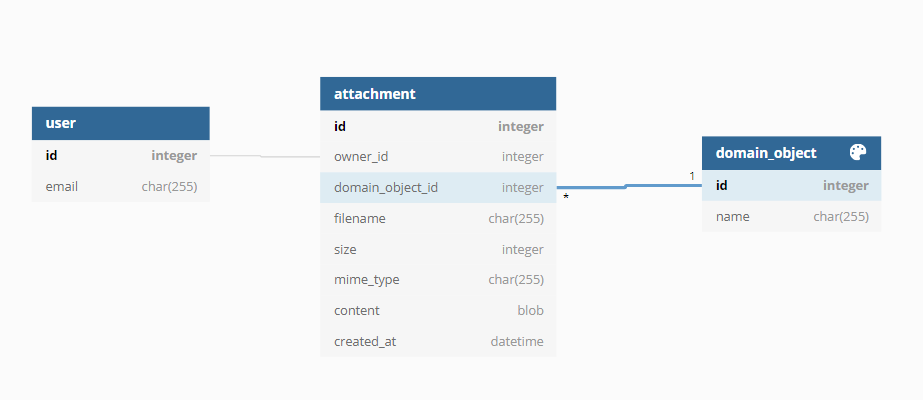
Je nach eingesetztem Framework ist die Speicherung des Bytestreams in die Tabelle attachment schnell umgesetzt. Eventuell nachträglich zu implementierende Autorisierungen für den Datei-Download können einfach implementiert werden. Die User Story ist damit umgesetzt. Während der Testphase oder des Go-Lives mit wenigen Anwendern und dementsprechend geringer Last ist die Web-Applikation wie gewünscht erreichbar. Der Auftraggeber ist vorerst zufrieden.
Was das Speichern von Blobs in Datenbanken bedeutet
Direkte Konsequenzen durch die Speicherung der BLOBs innerhalb der Datenbank
Durch das Speichern der Dateianhänge innerhalb der Tabelle attachment wächst die Gesamtgröße der Datenbank an. Blobs tragen dabei im Verhältnis zu den reinen (Text-)Daten am meisten zum Mengenzuwachs bei. Dies wiederum bedeutet:
- Die Festplatte bzw. das Dateisystem auf der sich die Daten der Datenbank befinden, beispielweise /var/lib/postgres, läuft mit der Zeit voll. 2. Exporte der unterliegenden Datenbank dauern länger.
- Die Last während der Replizierung von Datenbanken erhöht sich.
Das Wachstum der Datenbankgröße kann deutlich schneller erfolgen, als ursprünglich geplant: Bei SaaS-Anwendungen kann dies in der Startphase oft durch ein schnelles Wachstum der Benutzerbasis passieren. Ansonsten können während der Implementierung Bugs entstanden oder Randbedingungen nicht betrachtet worden sein:
- Bestehende Dateien werden bei einem erneuten Upload nicht ersetzt, sondern angehangen.
- Es existiert kein Limit für die Größe von angehängten Dateien.
Volllaufendes Dateisystem durch Blobs
Je nach Partitionierung der Betriebssystemumgebung kann ein vollgelaufenes Dateisystem dafür sorgen, dass eine Anmeldung per SSH nicht mehr ohne Weiteres möglich ist. Im einfachsten Fall können innerhalb der Datenbank keine Schreibänderungen mehr vorgenommen werden. Das bedeutet, dass auch Änderungen an anderen Tabellen fehlschlagen und die Web-Applikation nicht mehr uneingeschränkt nutzbar ist.
Da die Blobs aus der Datenbank nicht ohne Weiteres gelöscht werden können, muss das Dateisystem entweder vergrößert oder die Datenbank auf ein Dateisystem mit freiem Speicherplatz verschoben werden.
Exporte der Datenbank dauern länger
Je mehr Daten innerhalb der Datenbank gehalten werden, desto länger dauert auch der Export der Daten. Dies ist kurzfristig zu vernachlässigen, kann aber für den Produktivbetrieb langfristig problematisch werden.
Problematischer ist es hingegen, wenn Daten aus der Produktivdatenbank für die QS-Umgebung regelmäßig anonymisiert und exportiert werden. Innerhalb eines Continuous Integration/Deployment-Prozesses kann dies täglich öfter vorkommen und sorgt für zusätzliche Last auf der Produktivdatenbank. Hier ist abzuwägen, ob wirklich stunden- oder sogar minuten-aktuelle Daten benötigt werden. Andernfalls können die Exporte zwischengespeichert und später wiederverwendet werden.
Für den Fall, dass der letzte Stand der Produktivdatenbank eingespielt werden muss, sollten die Dateianhänge aus dem Export exkludiert werden. Dies kann in Abhängigkeit der Umgebung schwieriger zu implementieren sein und erhöht die Komplexität des Export-Prozesses.
Höhere Last während der Replizierung von Daten
Dies betrifft nur Anwendungen, für die bereits im Vorfeld eine horizontale Skalierung für die Datenbanken geplant worden ist. Es wird mehr Last bei der Replizierung zwischen dem Primary- und Secondary-Knoten erzeugt. Dies kann in ungünstigen Fällen dafür sorgen, dass die Replizierung in den out-of-sync Status fällt.
Wiederherstellung von einzelnen Blobs
Aufgrund von Compliance-Anforderungen kann es notwendig sein, dass Datensätze historisiert und/oder wiederherstellbar sein müssen. Die Historisierung der Dateien lässt sich implementieren, indem für jeden neuen Blob ein neues Tupel in der Datenbank persistiert wird. Dies führt allerdings dazu, dass jede neue Version eines Blobs vollständig in der Datenbank gespeichert werden muss.
Oracle’s Advanced LOB Deduplication erlaubt eine Deduplizierung. MySQL und PostgreSQL besitzen solch ein Feature hingegen nicht.
Folgeprobleme während der Software-Implementierungsphase
Die zuvor beschriebenen Problematiken sind während der Software-Entwicklung eher theoretischer Natur. Zuständig für das Lösen der Probleme während des Betriebs sind entweder die Datenbankadministratoren oder das DevOps-Team.
Sobald aber Teile der Anwendung Performance-Probleme aufweisen, wird zuerst das Software-Entwicklerteam konsultiert. Das folgende Sequenzdiagramm verdeutlicht den Ablauf, sobald Blobs aus der Datenbank geladen werden sollen. Blob-Service ist dabei austauschbar mit Applikationsserver, Microservice, Webserver oder auch einem PHP-Script.
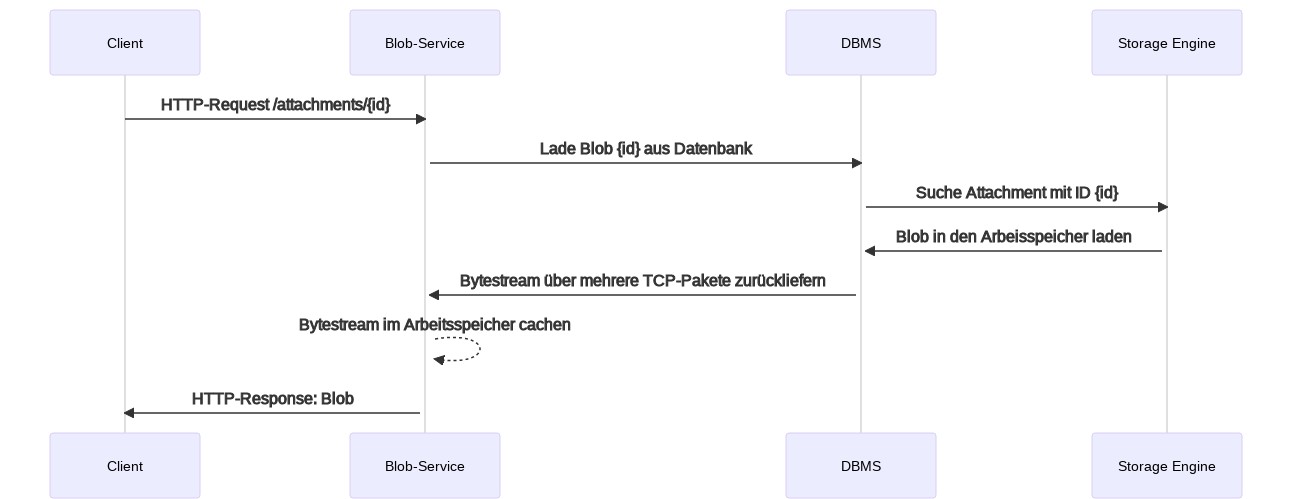
Für jede Anfrage eines Blobs durch den Client sind also sowohl der Blob-Service als auch das DBMS involviert. Die Antwortzeiten erhöhen sich somit.
Speicherverbrauch
Für jeden angefragten Blob muss der Service zuerst innerhalb der Datenbank das zugeordnete Tupel suchen. Das DBMS liefert den Datensatz über das TCP-Protokoll zurück. Der Service extrahiert den Blob aus dem Tupel und liefert diesen dann wiederum entweder an den Web- oder Applikationsserver zurück.
Normale Anwendungen erzeugen so eine hohen Arbeitsspeicherverbrauch: Der gesamte Bytestream des Blobs muss während der Anfrage im Arbeitsspeicher gehalten werden. Bei einer 20 MByte großen Datei würden sowohl auf DBMS-Seite als auch auf Seiten des Blob-Services zusätzlich 20 MByte im Arbeitsspeicher gehalten werden. Schon bei wenigen gleichzeitigen Anfragen kann dies zu einer vollständigen Auslastung des Arbeitsspeichers führen.
Reaktive Anwendungen, die z. B. Spring WebFlux in Kombination mit R2DBC einsetzen, können einzelne Chunks des Blobs an den Client zurückliefern. Der Arbeitsspeicherverbrauch wird dadurch minimiert. Allerdings erhöht sich die Komplexität der Anwendung bzw. des Microservices.
Upload von Blobs
Neben dem Download von Dateien muss auch der Upload betrachtet werden. Je nach eingesetzter Technologie müssen die passenden Konfigurations-Parameter gesetzt werden, damit größere Dateien überhaupt hochgeladen werden können:
| Plattform | Konfigurationsparameter |
|---|---|
| PHP | upload_max_filesize und post_max_size |
| MySQL | max_allowed_packet |
| Spring (Boot) | spring.servlet.multipart.max-file-size und spring.servlet.multipart.max-request-size |
Auch hier ist wichtig, dass das zugrundeliegende Betriebssystem über ausreichend Arbeitsspeicher verfügt, da ansonsten Java-basierte Anwendungen mit java.lang.OutOfMemoryError: Java heap space crashen können. Bei PHP-basierten Anwendungen kann es zusätzlich notwendig sein, den Parameter memory_limit anzupassen, falls die hochgeladene Datei im Arbeitsspeicher bearbeitet wird. Dies kann beispielsweise bei Kompressionen oder Skalierung von Bildern der Fall sein.
Caching
Um die Antwortzeiten zu reduzieren, kann der Blob-Service Caching implementieren. Das Caching der reinen Blobs innerhalb des Arbeitsspeichers ist aufgrund der Byte-Größe nicht praktikabel. Stattdessen kann der Blob-Service über HTTP-Header Cache-Control beeinflussen, wann der Client neue Versionen eines Blobs anfragen kann.
Speicherung von Blobs außerhalb der Datenbank
Um die bis hierhin thematisierten Probleme zu umgehen, kann eine der folgenden Alternativen in Betracht gezogen werden:
- Der Blob-Service liefert die Blobs direkt von der lokalen Festplatte oder einem verteilten Dateisystem (z. B. NFS, EFS) aus. Die Auslieferung kann dabei entweder vom Webserver bzw. Applikationsserver oder der Anwendung erfolgen. Die Metadaten des Blobs werden dabei weiterhin in der Datenbank gespeichert.
- Ein dedizierter Object Storage, z. B. AWS S3, Azure Blob Storage, Minio oder NetApp StorageGRID, kommt zum Einsatz. Die Metadaten werden dabei im Datenbankmanagementsystem und/oder im Object Storage gespeichert.
Direkte Auslieferung der Blobs durch den Service
Webserver sind darauf ausgerichtet, statischen Inhalt – also hochgeladene Blobs – performant bereitzustellen. Wenn der Blob-Service sich um die Auslieferung der Dateien kümmert, kann dies entweder mit oder ohne Involvierung des Web- oder Applikationsservers erfolgen. Die Metadaten werden dabei innerhalb der Datenbank gespeichert, so dass die Web-Applikation dem Benutzer Informationen zum Blob direkt anzeigen kann.
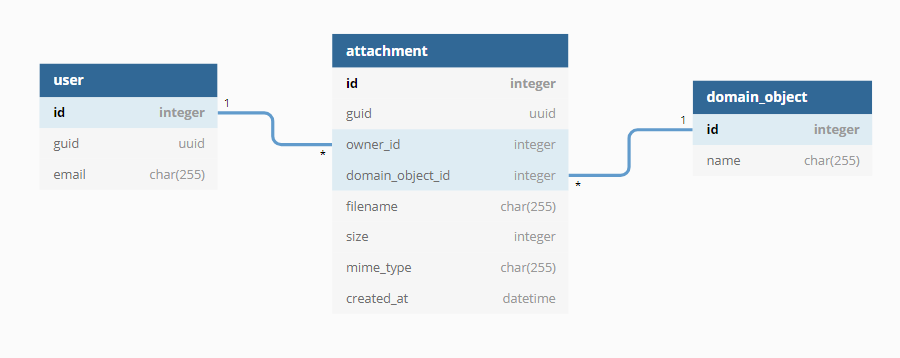
Beiden Vorgehen ist gemein, dass die Blobs im angebundenen Dateisystem gespeichert werden. Die definierte Backup-Strategie kann diese Dateien einbinden, so dass alte Versionen der Blobs wieder hergestellt werden können.
Redirect über eine URL
Bei dieser Methode erzeugt die Anwendung eine URL zu einem Verzeichnis, dass durch den Web- oder Applikationsserver direkt verarbeitet wird. Die Dateien werden dabei innerhalb einer Verzeichnisstruktur gespeichert, in der auch der Kontext – z. B. die GUID des aktuellen Tenants – hinterlegt ist. Der Dateiname selbst wird durch eine zufällige ID oder GUID ersetzt.
Vorteile:
- Implementierung ist vergleichsweise einfach.
- Sehr performant, da der Webserver alleine die Bereitstellung der Dateien vornimmt.
- Komprimierung der Blobs während der Übertragung kann direkt durch den Webserver erfolgen.
Nachteile:
- Eine Autorisierung auf die herunterzuladenden Dateien ist nicht bzw. nur mit zusätzlichem Aufwand auf Seiten des Webservers möglich.
- Obfuskation des Dateinamens ist keine Sicherheitsmaßnahme.
- Obfuskation des Dateinamens ist oft durch den Kunden auch nicht gewünscht.
Push durch den Blob-Service
Bei der Anfrage durch den Client erzeugt der Blob-Service auf Basis der Metadaten die passenden HTTP-Header. Der originale Dateiname kann dabei auch an den Client gesendet werden. Im Anschluss lädt der Blob-Service die Datei in den Arbeitsspeicher und sendet dann dessen Bytestream an den Client.
Vorteile:
- Autorisierung für Blobs kann innerhalb der Anwendung erfolgen. Ein Ausprobieren von URLs ergibt somit kein Ergebnis.
- Originaler Dateiname, MIME-Type und andere Metadaten bleiben während des Downloads erhalten.
Nachteile:
- Während des Downloads wird zusätzlicher Arbeitsspeicher benötigt.
- Logik zum Bereitstellen des Downloads muss in die Anwendung implementiert werden.
Auslieferung von Blobs durch ein Object Storage
Object Storages sind darauf spezialisiert, einzelne Blobs über eine eindeutige URL bereitzustellen. Mit Hilfe von AWS S3 oder Azure Blob lassen sich beispielsweise zeitlich begrenzt gültige URLs erzeugen, in der eine Datei herunter- aber auch hochgeladen werden kann. Je nach Object Storage existieren Lösungen zur Versionierung und auch die Möglichkeit, die Blobs in langsamere, und damit günstigere, Storages zu verschieben.
Obwohl z. B. AWS S3 auch Metadaten speichern kann, werden diese oft zusätzlich in der Datenbank vorgehalten. Dies reduziert die Anfragen an die API von S3.
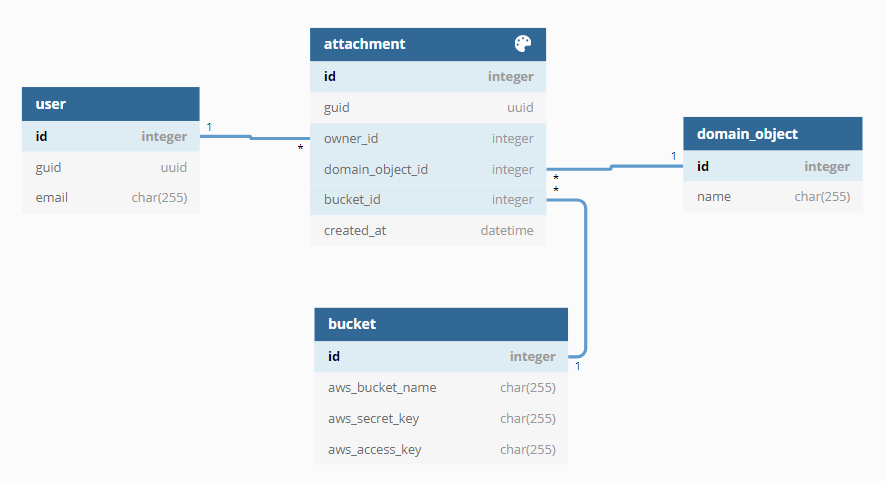
Vorteile:
- Up- und Download wird komplett außerhalb der Anwendung verlagert. Besonders bei später notwendiger Skalierung kann beispielsweise ein CDN wie CloudFront genutzt werden.
- Datensicherung durch den Object Storage-Provider
Nachteile:
- ggf. Compliance-Probleme wenn die Dateien bei einem Cloud-Provider gespeichert werden
- ggf. je nach eingesetztem Produkt zusätzliche Kosten für Traffic und API-Anfragen
Risiko- und Kostenbetrachtung
| Speicherung von Blobs in ... | Risiko | Zu erwartende Kostenfaktoren |
|---|---|---|
| Datenbank | Hoch |
|
| lokalem oder verteiltem Dateisystem | Mittel |
|
| Object Storage | Gering |
|
Fazit
Auch wenn eine Speicherung von Blobs innerhalb einer Datenbank auf den ersten Blick attraktiv aussieht, raten wir von solch einer Architekturentscheidung ab. Je nach Risikoabwägung und verfügbarem Budget empfehlen wir entweder die Nutzung eines lokalen oder verteiltem Dateisystems und Bereitstellung der Blobs durch die Anwendung oder aber den Einsatz eines passenden Object Storages.
